This step-by-step guide shows how to use very large models (e.g., large language models) in your software submissions to TIRA. The cluster infrastructure that hosts TIRA has several GPUs available, and we currently allow that a software submission can take up to one 40GB A100 GPU for execution.
We will use the PAN@CLEF24 Generative AI Authorship Verification Task as example, but all steps transfer to the other tasks as well.
High-Level Overview
Conceptually, software submissions in TIRA have no access to the internet during their execution to improve reproducibility (e.g., the software does not depend on external dependencies that might become unavailable in a year) and ensure that software can run on confidential or private test sets. Small to medium sized models can be embedded into the Docker image, but for large models (especially when a few large models are combined in a submission), it might be unrealistic and too redundant to add them to the Docker image. We therefore allow that the weights of large models can be mounted read-only into the Docker container during execution.
In the following, we assume that you have Docker, Python (>= 3.7), tira (pip3 install -U tira), and huggingface-hub (pip3 install huggingface-hub) installed on your machine.
Step 1: Ensure that your Software works on your machine
We will use the pan24 ai authorship baseline as example. This baseline uses two large language models available on Hugging Face, tiiuae/falcon-7b and google-t5/t5-large, to detect if text is written by an human or an AI.
First, we use the huggingface-cli to download those models on our machine:
huggingface-cli download google-t5/t5-large
huggingface-cli download tiiuae/falcon-7b
Now that we have the models on our machine, we can run the baseline on our machine via (please note that the line breaks are for linux):
tira-run \
--gpus all \
--image ghcr.io/pan-webis-de/pan24-generative-authorship-baselines:latest \
--mount-hf-model tiiuae/falcon-7b google-t5/t5-large \
--input-dataset generative-ai-authorship-verification-panclef-2024/pan24-generative-authorship-tiny-smoke-20240417-training \
--command 'baseline detectllm --base-model tiiuae/falcon-7b --perturb-model google-t5/t5-large $inputDataset/dataset.jsonl $outputDir'
Lets look into the essential flags of this command in more detail:
--imagespecifies the docker image, in this case the docker image with the code and dependencies for the pan24 ai authorship baseline--mount-hf-modelspecifies which models from Hugging Face will be mounted read-only into the container. This flag respects theHF_HOMEandHF_HUB_CACHEenvironment variables of the huggingface-cli on the host.--input-datasetpoints to some dataset on which we run the software, in this case, a tiny smoke-test dataset with 10 examples to ensure that the software works--commandspecifies the command that is executed in the container, a software is expected to process the data in the directory$inputDatasetand to write its outputs to$outputDir.
We run this and verify that the output (in the tira-output directory) is correct, if this is the case, we can continue.
Step 2: Upload the Model Weights to TIRA
We assume that the models that we want to use are publicly available on Hugging Face. It is also possible to use private or unpublished models (in such cases, we give you access to upload the model via scp to TIRA.)
To ensure that your models are available in tira, please go to your submission page and click on “Uploads”. Select “I want to upload a model from Hugging Face” and click next.
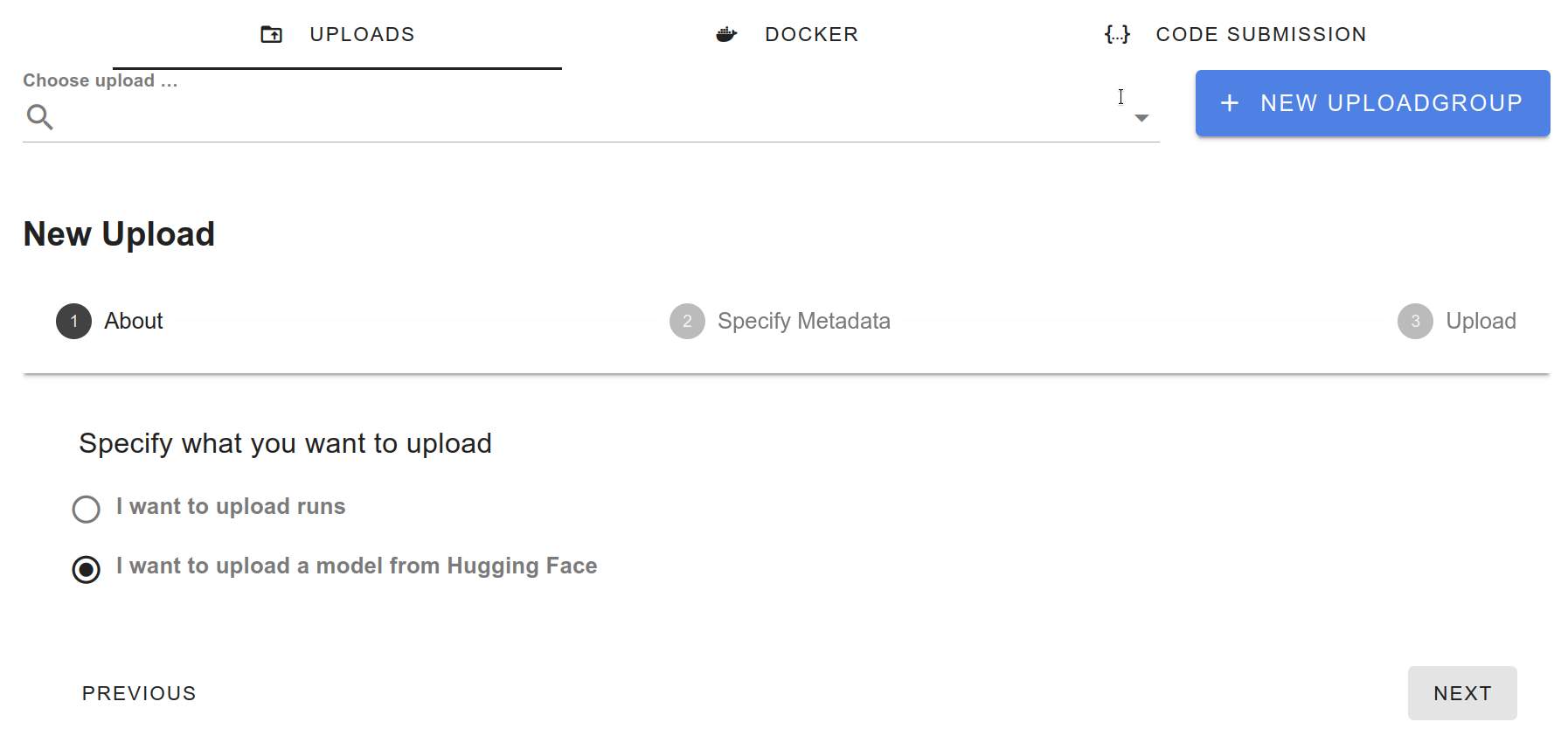
Specify the model(s) that you want to use. For completeness, the UI shows the code snippet that it will use to download the model:
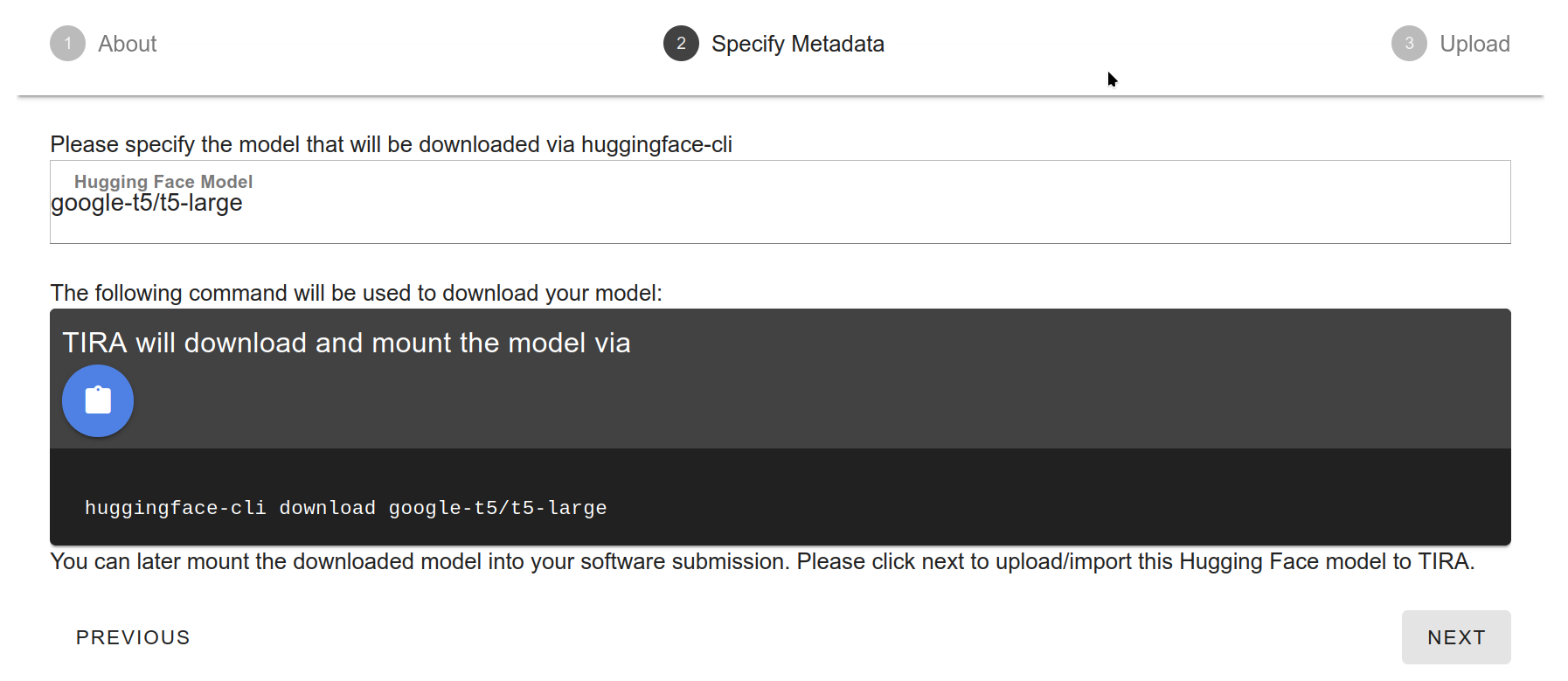
TIRA will take care to not redundantly load models:

As soon as we ensured that the models are available in TIRA, we can continue.
Step 3: Upload your Software and Run it in TIRA
Please follow the step-by-step available on your submission page after clicking on “Docker” → “New Submission”. Basically, you only have to run tira-cli login ... and re-execute the tira-run ... command from above whith an appended --push true to upload the software to tira.
As soon as the software was uploaded, you can select it in the TIRA UI and run it. The UI will show which model weights are (additionally to the input) mounted read-only into the container.
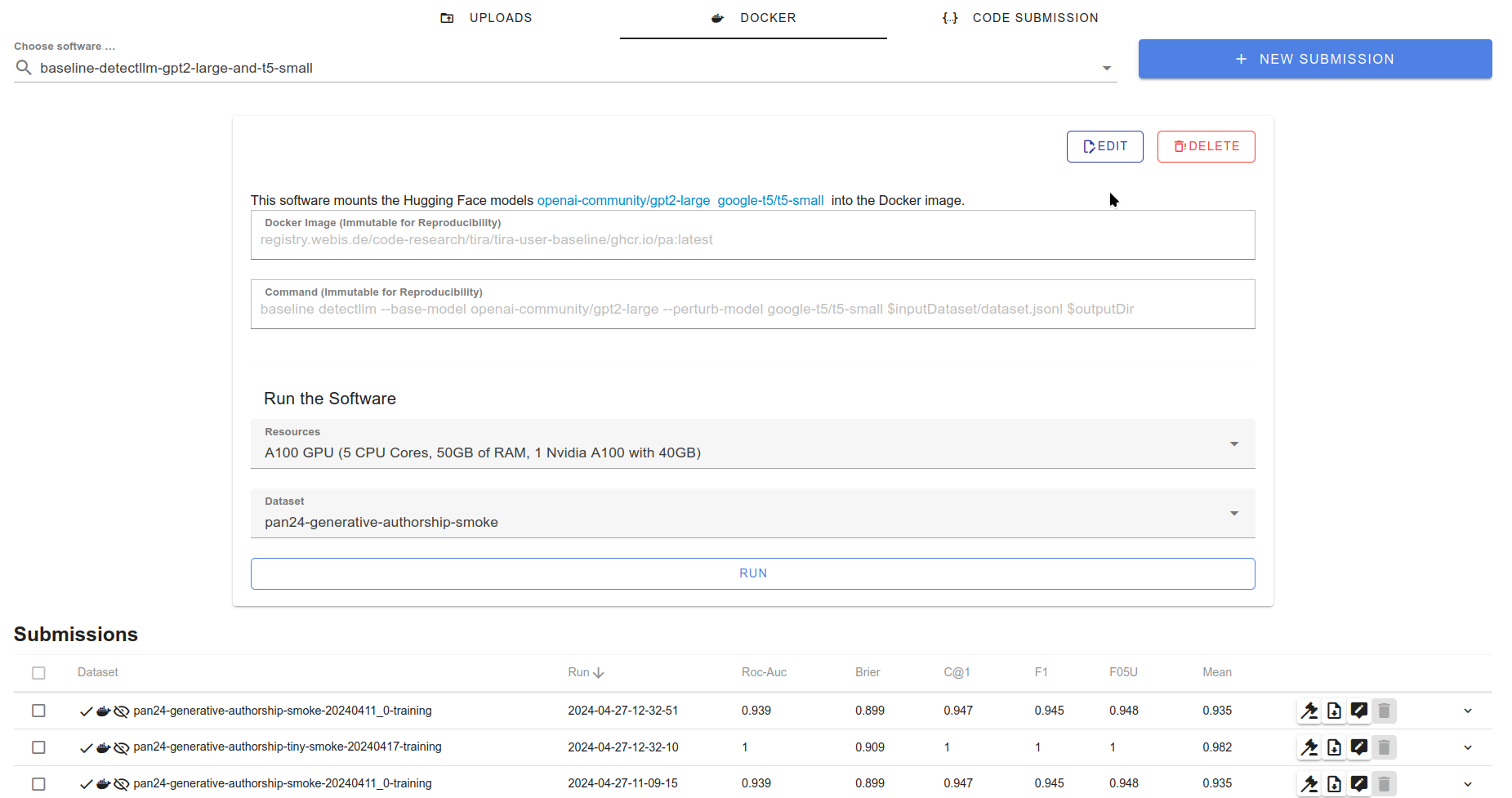
Thats it, if you have any questions, problems, or suggestions, please do not hesitate to contact us.