Hi, im trying to run my docker container on the 2023 Dataset for the Task “Image Retrieval for Arguments”. Sadly, its missing. And none of the validation datasets contain image-text.txt files. How should I submit our software?
I copied the dataset, but it seems the current version of TIRA can not handle the size. Can you tell me which of the input files you are using, so that I can, for now, reduce the dataset size so that you can at least submit while we are looking for a permanent solution?
Hi, the TIRA team now fixed the issue regarding large datasets (or rather, as it turned out, datasets with many files).
I now updated the datasets in TIRA:
main-2023 (full rank): this is the dataset you can use for submission
toy-2023 (full rank): this is the same dataset, but with only 3 topics and only 23 images, so you can use that to test your approach.
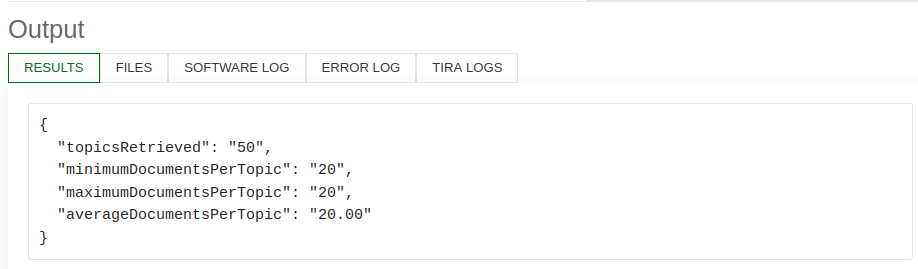
For both datasets a validator script is run at the end to check the output format. You should then be able to see in TIRA something like this when you click on “EVALUATION”: