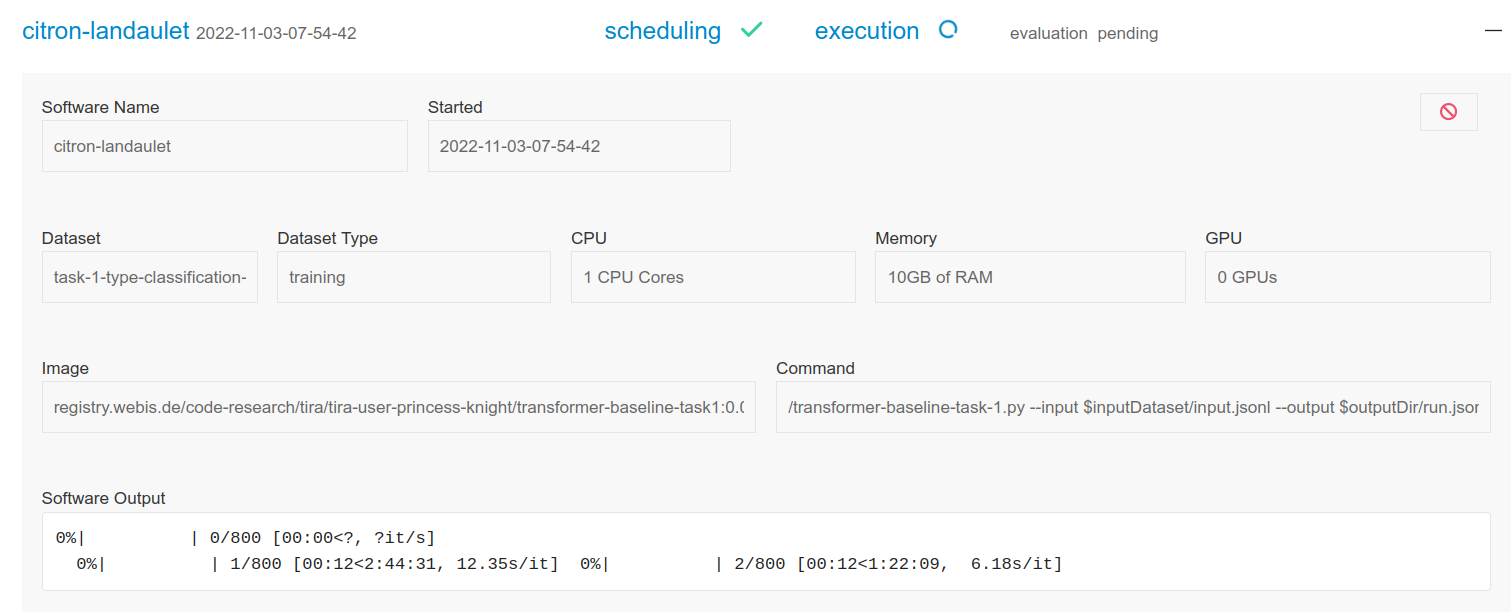
I have this problem in general, but i will explain it with the Transformer Baseline1:
Instead of downloading the transformer when creating the Container like in Baseline 1, I downloaded the transformer model beforehand and used the copy command to get it into the container.
So that I can later upload my own transformers to Tira with this.
That means I have removed this Dockerfile part:
RUN apt-get update \
&& apt-get install -y git-lfs wget \
&& wget 'https://raw.githubusercontent.com/tira-io/tira/development/application/src/tira/templates/tira/tira_git_cmd.py' -O '/opt/conda/lib/python3.7/site-packages/tira.py' \
&& git clone 'https://huggingface.co/webis/spoiler-type-classification' /model \
&& cd /model \
&& git lfs install \
&& git fetch \
&& git checkout --track origin/deberta-all-three-types-concat-1-checkpoint-1000-epoch-10 \
&& rm -Rf .git
Downloaded the files beforehand and instead packed the files(config.json,pytorch_model.bin,special_tokens_map.json,training_args.binm,model_args.json,scheduler.pt,tokenizer_config.json and vocab.json) with the COPY command into a subfolder (in my case /checkpoint and not /model).
To me, the container seems to have the same content.
I only changed the folder name in the code.
Locally, I can execute everything without a container, but something goes wrong in the container and I get this error when trying to execute the container:
Traceback (most recent call last):
File "/transformer-baseline-task-1.py", line 63, in <module>
run_baseline(args.input, args.output)
File "/transformer-baseline-task-1.py", line 55, in run_baseline
for prediction in predict(input_file):
File "/transformer-baseline-task-1.py", line 42, in predict
model = ClassificationModel('deberta', './checkpoint', use_cuda=False)
File "/opt/conda/lib/python3.7/site-packages/simpletransformers/classification/classification_model.py", line 471, in __init__
tokenizer_name, do_lower_case=self.args.do_lower_case, **kwargs
File "/opt/conda/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 1784, in from_pretrained
**kwargs,
File "/opt/conda/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 1930, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/models/deberta/tokenization_deberta.py", line 134, in __init__
**kwargs,
File "/opt/conda/lib/python3.7/site-packages/transformers/models/gpt2/tokenization_gpt2.py", line 192, in __init__
with open(merges_file, encoding="utf-8") as merges_handle:
TypeError: expected str, bytes or os.PathLike object, not NoneType
Which I can’t understand, because the files should actually be there.
With the >ls foldername< I can also verify that the Transformer data is in the container.
I tried loading the model with full path and relative path, but I have no idea how to fix this. Because the files are in the container and can be loaded locally and in the baseline Transformer Container via Huggingface ![]() .
.