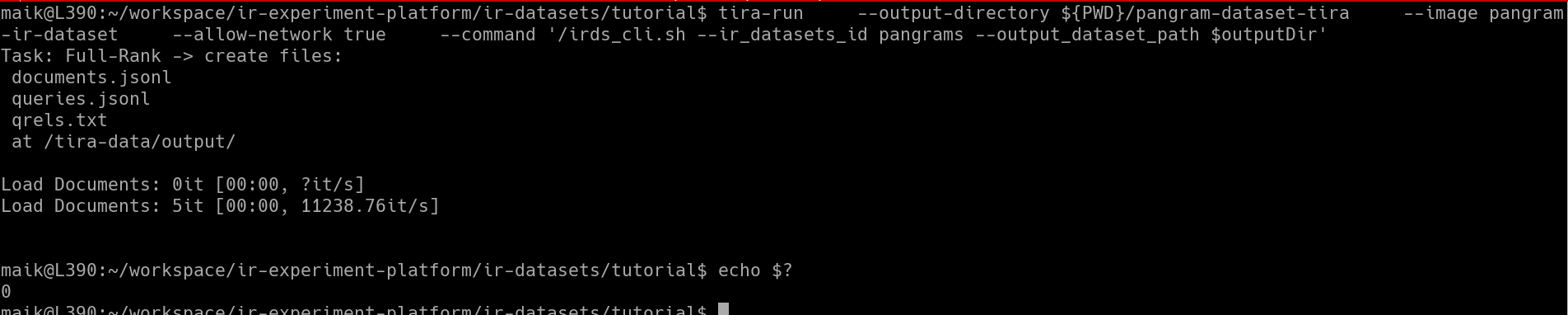
Hey @maik_froebe,
I’m not the original author of this question but we encountered some problems using the steps you described. With the ‘downloading method’ the tira-run command runs perfectly fine for us, but when we switched to your method we only got failed attempts.
There was no error message, the process just failed outright without any additional information:
Task: Full-Rank → create files:
documents.jsonl
queries.jsonl
qrels.txt
at /tira-data/output/
Load Documents: 0it [00:00, ?it/s]
Load Documents: 610it [00:00, 6095.01it/s]
Load Documents: 1801it [00:00, 9503.96it/s]
Load Documents: 3154it [00:00, 11340.55it/s]
Load Documents: 4508it [00:00, 12204.56it/s]
Load Documents: 5808it [00:00, 12487.90it/s]
Load Documents: 7121it [00:00, 12703.89it/s]
Load Documents: 8392it [00:00, 12282.92it/s]
Load Documents: 9623it [00:00, 11580.74it/s]
Load Documents: 10790it [00:00, 10888.25it/s]
Load Documents: 11890it [00:01, 10906.01it/s]
Load Documents: 13216it [00:01, 11582.18it/s]
Load Documents: 14470it [00:01, 11848.16it/s]
Load Documents: 15663it [00:01, 10933.89it/s]
Load Documents: 17523it [00:01, 13066.08it/s]
Load Documents: 18983it [00:01, 13497.31it/s]
Load Documents: 20357it [00:01, 13560.25it/s]
Load Documents: 21730it [00:01, 12675.70it/s]
Load Documents: 23020it [00:01, 12498.30it/s]
Load Documents: 24285it [00:02, 12399.08it/s]
Load Documents: 25782it [00:02, 13129.42it/s]
Load Documents: 27628it [00:02, 14669.47it/s]
Load Documents: 29109it [00:02, 14516.72it/s]
Load Documents: 30571it [00:02, 14416.66it/s]
Load Documents: 32020it [00:02, 14356.90it/s]
Load Documents: 33461it [00:02, 13664.35it/s]
Load Documents: 34837it [00:02, 13236.28it/s]
Load Documents: 36320it [00:02, 13686.01it/s]
Load Documents: 37840it [00:02, 14117.42it/s]
Load Documents: 39260it [00:03, 13663.94it/s]
Load Documents: 40828it [00:03, 14240.14it/s]
Load Documents: 42605it [00:03, 15264.61it/s]
Load Documents: 44888it [00:03, 17481.98it/s]
Load Documents: 47090it [00:03, 18820.22it/s]
Load Documents: 49226it [00:03, 19572.96it/s]
Load Documents: 51192it [00:03, 18738.33it/s]
Load Documents: 53079it [00:03, 17740.63it/s]
Load Documents: 53673it [00:03, 13915.08it/s]